Handling missing data is a crucial part of the data preprocessing stage in any data science or machine learning project. Missing values can distort analysis, reduce model accuracy, and lead to biased results if not treated properly. Fortunately, several imputation techniques are available to manage this issue effectively. If you want to learn these methods in depth, consider joining the Data Analyst Course in Mumbai at FITA Academy. It’s a great way to build your skills and confidence in handling real-world data challenges.
In this blog, we will explore common imputation methods, their advantages, and when to use them. Whether you are dealing with a small dataset or working on a complex machine learning pipeline, understanding these techniques will help improve your data quality and model performance.
Why Missing Data Matters
Missing data occurs for various reasons. It could be due to human error, sensor failure, data corruption, or simply because a value was not applicable in a given context. Regardless of the cause, ignoring missing data is rarely a good option.
Datasets with missing values can prevent certain algorithms from functioning correctly. Some models require a complete dataset to train, while others may handle missing values poorly, leading to unreliable predictions.
Therefore, before feeding data into a model, it is essential to detect and treat missing values using appropriate imputation methods. To learn these techniques, the Data Analytics Course in Kolkata offers comprehensive training to help you handle missing data effectively.
Types of Missing Data
Before choosing an imputation strategy, it helps to understand the type of missing data you are dealing with. There are three main types:
- Missing Completely at Random (MCAR): The missingness has no pattern and is independent of any variables in the dataset.
- Missing at Random (MAR): The missingness is related to some of the observed data but not the missing data itself.
- Missing Not at Random (MNAR): The missingness is related to the value that is missing, which can make it harder to impute accurately.
Knowing the type of missing data helps in selecting the most suitable imputation technique.
Common Imputation Techniques
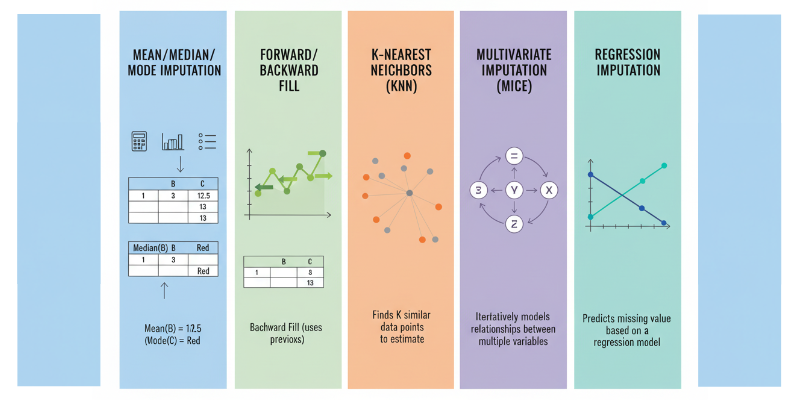
1. Mean, Median, or Mode Imputation
One of the simplest and most commonly used techniques is replacing missing values with the mean, median, or mode of the column.
- Mean imputation works best for numerical data with a normal distribution.
- Median imputation is better when data is skewed.
- Mode imputation is ideal for categorical variables.
This approach is simple to execute and is effective when just a minimal part of the data is absent. However, it can reduce data variability and introduce bias if overused.
2. Forward or Backward Fill
This technique is often used with time-series data. Forward fill replaces missing values with the previous non-missing value, while backward fill uses the next valid value.
It maintains temporal relationships but may not be suitable for datasets where the context or value changes frequently. To gain a deeper understanding of such data challenges, consider enrolling in the Data Analytics Course in Hyderabad, where practical techniques like these are taught in detail.
3. K-Nearest Neighbors (KNN) Imputation
KNN imputation fills in missing values based on the values of the nearest neighbors. It uses a distance metric, typically Euclidean distance, to find observations with similar characteristics.
This method works well when data has a strong relationship between features. Nevertheless, it can require significant computational resources, particularly when dealing with extensive datasets.
4. Multivariate Imputation by Chained Equations (MICE)
MICE is an advanced technique that builds a regression model for each feature with missing values. It then predicts the missing values based on other variables iteratively.
This method handles complex relationships between variables and provides more accurate imputations. It is widely used in research and clinical studies but requires more computational power and time.
5. Regression Imputation
Regression imputation estimates the missing value by considering it as a dependent variable within a regression model. The independent variables are the other features in the dataset.
It maintains logical relationships between variables but may underestimate variability if the same prediction is used repeatedly.
Choosing the Right Method
There is no one-size-fits-all approach when it comes to imputation. The best technique depends on:
- The size and nature of your dataset
- The type and proportion of missing data
- The relationships among your variables
- The final goal of your analysis or model
In many cases, experimenting with multiple techniques and validating the results through model performance is the best approach.
Missing data is a common but manageable issue in data analysis. Imputation techniques provide practical ways to fill in the gaps and create a more robust dataset. Whether employing straightforward techniques such as mean imputation or utilizing more complex approaches like MICE, properly addressing missing data can greatly impact the effectiveness of your analysis. If you want to master these skills, the Data Analyst Course in Pune offers focused training to help you excel in real-world data projects.
By applying the right imputation techniques, you can ensure that your models are more accurate, reliable, and ready for real-world use.
Also check: Anomaly Detection in Business Analytics